Published on
July 1, 2026


If I had to boil this down to one point, it’s this: the best TLH setup usually isn’t one API model by itself. It’s a mix of fast monitoring, wash-sale checks across household accounts, and portfolio rules that keep trades from creating new problems.
Here’s the short version:
The numbers make the trade-off clear. Automated TLH can add about 0.75% to 1.50% per year, while manual methods often land closer to 0.20% to 0.40%. And because losses can offset gains plus up to $3,000 of ordinary income each year, the setup behind the API matters more than many teams think.
If I were choosing, I’d keep my eye on four things:
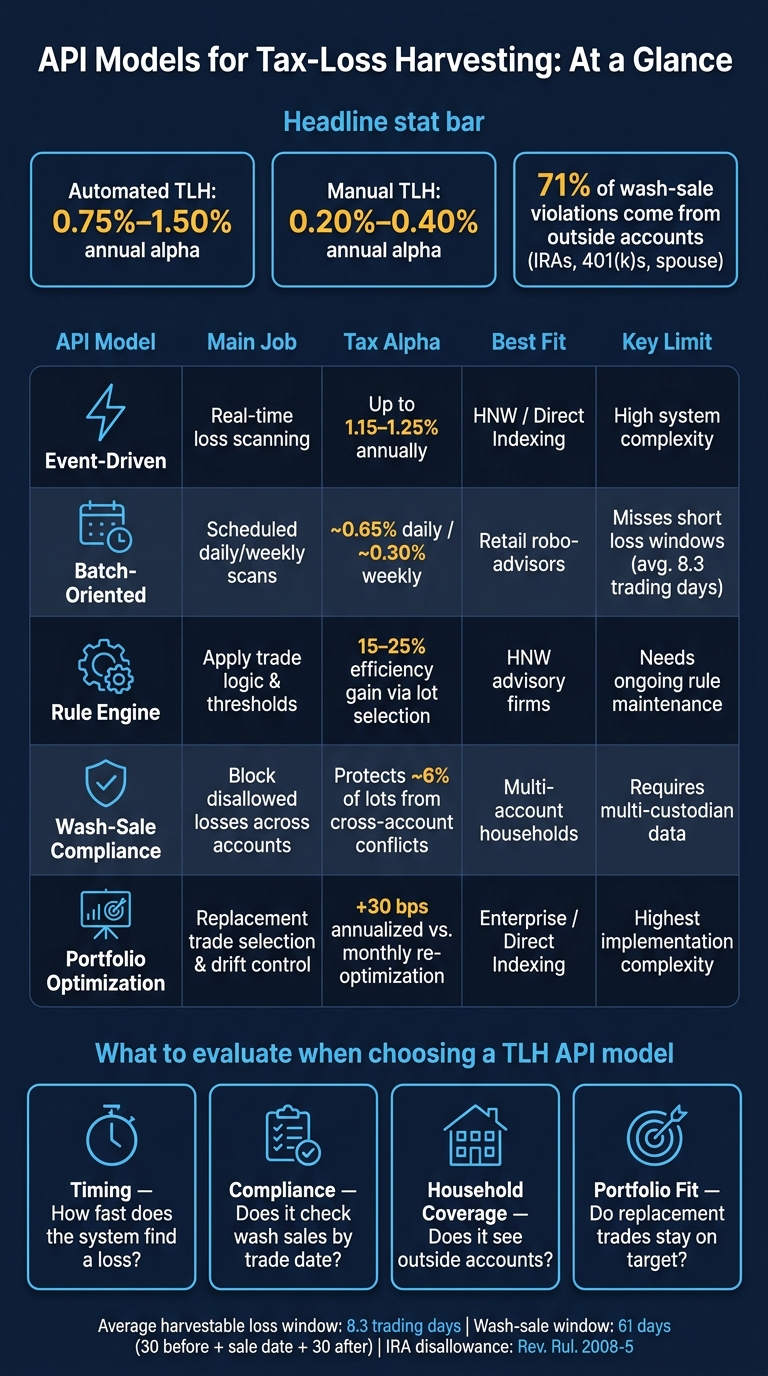
API Models for Tax-Loss Harvesting: Side-by-Side Comparison
| Model | Main job | Main upside | Main limit | Best fit |
|---|---|---|---|---|
| Event-driven | Scan for losses in real time or near real time | Finds more short loss windows | More system load and setup work | Direct indexing, larger taxable accounts |
| Batch | Scan on a daily or weekly schedule | Simple to run | Misses many short-lived losses | Smaller books, basic TLH workflows |
| Rule engine | Apply trade logic and thresholds | Better trade filtering | Needs steady rule maintenance | Firms that want policy control |
| Wash-sale compliance | Block disallowed losses across accounts | Closes the outside-account gap | Needs linked-account data | Households with IRAs, 401(k)s, spouse accounts |
| Portfolio optimization | Choose replacement trades and control drift | Keeps tax moves aligned with allocation | Hardest to build well | Enterprise and direct-indexing platforms |
My takeaway: if you only need a simple starting point, batch is fine. If timing and tax alpha matter more, event-driven plus rule logic tends to do better. And once household accounts enter the picture, wash-sale checks and portfolio coordination move from “nice to have” to must-have.
That’s the frame I’d use to read the rest of the article.
Event-driven APIs plug into custodial data feeds and watch unrealized gains and losses in real time. So instead of waiting for a scheduled review, the system sends a trade signal as soon as a position hits a preset loss threshold, whether that's based on a dollar loss or a percentage drop.
The appeal is simple: speed. But that only works if live data, compliance checks, and trade execution all happen in real time too.
Most of the gap comes down to scan frequency. Hourly scanning picks up 14–18 harvestable events per 50-position portfolio each year and produces 0.95% annual tax alpha. Moving to 15-minute scans pushes that to 1.15% [1].
That difference matters because volatile markets can open and close these windows fast.
Some systems also apply volatility overrides. For example, scan frequency can shift from hourly to every 15 minutes when market volatility moves above a set trigger such as VIX > 25 [2].
In event-driven setups, wash-sale rules work as a pre-trade control. Once a sale goes through, the system updates a restricted list across taxable, IRA, 401(k), and spouse accounts so it can block repurchases during the 61-day window [2] [4].
That isn't a small detail. 71% of wash-sale violations in managed accounts come from purchases in outside accounts, including 401(k)s or spouse accounts [1].
One more point that trips people up: track wash-sale windows by trade date, not settlement date. If you use settlement date, you can create 1- to 2-day boundary errors [4].
Cloud-based event-driven systems handle year-end surges well, with scan frequency adjusted around API limits and infrastructure cost [2] [5]. For active strategies, position feeds need sub-second latency so unrealized P/L stays current [5].
A flat dollar threshold sounds neat, but it usually leaves money on the table. A better setup uses dynamic thresholds linked to position size, marginal tax rate, and transaction costs [2] [5].
Minimum Loss = (Transaction Cost + Tracking Cost) ÷ Marginal Tax Rate
You can also add a 15-minute advisor approval window. That gives advisors time to review trades without letting the market window slip away [2].
If continuous monitoring doesn't add much, scheduled runs are often the lower-cost operating model.
Batch-oriented APIs run harvesting scans on a set schedule, usually daily or weekly. They’re easier to run than always-on monitors, but there’s a tradeoff: they respond later. If real-time monitoring doesn’t justify the added cost, batch scans are the simpler fallback.
Daily batch scanning is the industry baseline. It produces about 0.65% in annual tax alpha and picks up around 8–12 harvestable events per 50-position portfolio each year [1]. Move from daily to weekly runs, and performance drops fast. Annual tax alpha falls to 0.30%, which is a 55% reduction [1].
The reason comes down to timing. The average harvestable loss window lasts only 8.3 trading days [1]. That’s shorter than a weekly monitoring cycle, so a weekly process can miss losses before they disappear.
The 2025 data shows this pretty clearly. Only 31% of S&P 500 stocks ended the year down 5% or more, but nearly 83% had a drawdown of at least 5% at some point during the year [9]. In plain English, the loss was often there for a while, then gone. Infrequent batch runs miss a lot of that window before prices bounce back.
Batch systems do a decent job with wash-sale screening inside managed accounts, but the outside-account gap is still a problem. The 61-day wash-sale window has to be checked across linked accounts, including IRAs, 401(k)s, and spousal accounts [4][5]. That cross-account visibility is still the main compliance weak spot.
One detail matters more than it may seem: batch algorithms should use trade dates, not settlement dates, when calculating the 61-day window. Settlement-date logic can create 1–2 day boundary errors near the edges of the window [4].
Lot selection matters too. APIs should use specific lot identification, often HIFO (Highest In, First Out), instead of FIFO or average cost, to harvest the largest possible loss per transaction [2].
Batch processing works well at scale, especially for large account books. End-of-day scheduled jobs reduce API rate-limit pressure and make server-side processing easier to plan. That matters during heavy-volume periods like November and December. Cloud-based architectures can supply the elastic compute capacity needed for year-end harvest optimization [5].
The downside is built in. By the time a daily batch run starts, some loss windows have already closed.
Batch models are also good at coordination. Because runs happen at set intervals, it’s easier to line up harvesting with rebalancing and cash flow events [3]. Client-specific restrictions, like do-not-sell lists or ESG exclusions, can be folded into the same run [5].
They also make it easier to:
When those checks need to happen at each decision point instead of on a schedule, rule engines take over.
Rule-engine APIs sit in the middle of batch and event-driven setups. They keep watching positions between scheduled runs, but they only place trades when both policy rules and the dollars-and-cents math line up. That makes them a strong fit for platforms that need faster action than batch jobs, without handing the keys to pure trigger-based automation.
Rule engines harvest only when the expected tax savings are greater than the trading and tracking costs. In plain English: a paper loss alone isn't enough. The trade still has to make sense after fees and tracking drag are included.
Using specific lot identification instead of average-cost methods improves harvesting efficiency by 15% to 25% [2][1]. That edge matters. It helps rule engines beat batch scanning in many cases because they move sooner and skip trades that look good at first glance but don't pay off once costs are added in.
Rule engines treat wash-sale risk as a live limit, not a box to check later. Cross-account coverage can extend to taxable accounts, IRAs, 401(k)s, and spousal accounts.
One detail people often miss is dividend reinvestment. The engine should flag and temporarily disable automatic dividend reinvestments during the 30-day post-harvest window, since an automatic reinvestment in the same security can trigger a wash sale if it is not suppressed [8].
That said, one gap still tends to stick around: cross-account wash-sale detection. That's the point where dedicated compliance APIs start to matter.
Rule engines can adjust thresholds based on position size, tax bracket, and state tax rates. So the logic for a $5,000 position should not look the same as the logic for a $500,000 position. A one-size-fits-all rule set sounds neat on paper, but it falls apart fast in live portfolios.
They also recover more chances than daily batch runs because they act sooner. Scan cycles usually run hourly to every 15 minutes [1]. That shorter loop can make a real difference when markets move and loss windows open, then close, in a hurry.
Tax-loss harvesting doesn't happen in a vacuum. It bumps into rebalancing all the time. Rule engines help cut that friction.
A live restricted list can stop rebuys during rebalancing, so a normal rebalance trade doesn't accidentally buy back a position that was just harvested [6][4]. That saves teams from the kind of own goal that turns a clean harvest into a wash-sale headache.
Automation also cuts TLH administration from 55 minutes per event to about 1 minute [6]. That's a big drop. And it does more than save staff time. It helps keep tax alpha intact by reducing avoidable trade blocks and rebalancing conflicts, while leaving the cross-account wash-sale gap for dedicated compliance APIs to handle.
Rule engines decide when to harvest. Wash-sale APIs decide whether the loss still counts.
Their job is simple in theory but unforgiving in practice: stop disallowed losses by checking whether a harvested position clears household-level purchase checks, including held-away accounts. That’s why full household visibility sits at the center of the whole process.
Held-away accounts are where most compliance problems start. So if a wash-sale API can’t read across the full household, it’s operating with a blind spot.
About 71% of wash-sale violations in managed accounts come from accounts like IRAs, 401(k)s, and spouse accounts [1]. The wash-sale window runs 61 days total: 30 days before the sale date, the sale date itself, and 30 days after. And this is where systems can trip over tiny timing mistakes. Trade-date logic needs to replace settlement-date logic to avoid boundary errors [4].
There’s also a harsher edge case. If the triggering purchase happens inside an IRA, Rev. Rul. 2008-5 means the loss can be permanently disallowed because IRAs have no external cost basis to adjust [4].
Once compliance is cleared, portfolio rules can block conflicting trades and substitutions.
CUSIP matching by itself won’t cut it. A solid engine needs a substitutability matrix that treats share classes and index-tracking ETFs as substantially identical [4].
That matters more than it may seem at first glance. About 6% of harvestable lots in real portfolios get blocked by cross-account wash-sale conflicts [7]. You only see that drag when the API has visibility across the entire household.
When a harvest trade goes through, the API should immediately push that security onto a real-time restricted list shared across every linked account in the household [2]. That stops automated rebalancing or manual trades from buying the position back during the 30-day window.
Audit records should capture:
Once a harvest clears wash-sale rules, the next step is simple to say but harder to do: the replacement trade still has to fit the portfolio.
Optimization APIs help turn harvested losses into replacement trades that still line up with target allocation, liquidity needs, and client restrictions. In plain English, they try to keep the tax move from throwing the rest of the portfolio off balance.
They usually rank short-term losses first, since those can offset income taxed at ordinary rates of up to 37% [2]. That matters because a loss isn't just a loss on paper. Used well, it can cut a client's tax bill where rates hit hardest.
These APIs tend to work best with granular tax-lot accounting and direct-indexed sleeves. That's where the engine has more room to choose lots and swap positions without making the portfolio look like a different strategy. Daily re-optimization can add about 30 bps of annualized tax alpha compared with monthly runs [9].
A replacement can't be substantially identical to the position that was sold. That's the line firms have to respect.
Optimization APIs handle this by screening replacements through factor exposure mapping across style, size, and sector dimensions. The goal is to stay close enough to the original holding that the portfolio keeps its intended shape, while still avoiding "substantially identical" classifications. In practice, that usually means keeping 85% to 95% correlation with the original position [5].
All of that optimization logic has to run across a lot of accounts without slowing execution. If the system takes too long, the window can close, prices can move, and the trade loses some of its edge.
These APIs matter most when short re-optimization windows have to be processed across large household books without delaying order generation.
Every harvest trade has to balance tax value against drift from target allocation, liquidity needs, and client-specific rules [2]. One tax win can create three other problems if the system isn't watching the full picture.
A key rule here: use trade dates, not settlement dates, when measuring the 61-day window [4]. That's the kind of detail that sounds small until it causes a compliance issue.
APIs also need to coordinate TLH with rebalancing and portfolio-rule management. That means balancing tax optimization against cash flow needs and ESG constraints at the same time [3].
Those trade-offs set up the comparison below.
These models diverge most on latency, compliance scope, and portfolio control. The tables below boil those trade-offs down.
| Criterion | Event-Driven (Continuous/Hourly) | Batch (Daily/Weekly) |
|---|---|---|
| Latency | Sub-second to 15 minutes | 24 hours to 7+ days |
| Data Freshness | Intraday/real-time pricing | End-of-day or stale pricing |
| Throughput | Continuous, high-frequency processing | High-volume, scheduled processing |
| Overtrading Risk | Higher; requires dynamic thresholds | Lower; limited by cycle frequency |
| Operational Complexity | High; requires real-time data sync | Low; "cron job"-style execution |
| Scale Fit | HNW / active robo-platforms | Mass-affluent accounts / simpler RIA books |
The same divide shows up in decision logic too. Rules tend to be simpler. Optimization gives you more room to shape outcomes.
| Criterion | Rules (Fixed Thresholds) | Optimization-Based |
|---|---|---|
| Transparency | High; easy to explain to clients and CPAs | Lower; multi-variable optimization |
| Customization | Limited to fixed dollar/percent rules | High; factor exposure, ESG mapping |
| Regulatory Adaptability | Easier to encode bright-line tax rules; struggles with "substantially identical" securities | Highly adaptable; can use a substitutability matrix |
| Multi-Asset Flexibility | Basic; often limited to simple ETF-for-ETF or stock-for-ETF swaps | Strong; essential for complex portfolios like municipal bonds |
Rule-based engines are easier to walk through with clients. Optimization-based engines make more sense for direct indexing and multi-asset portfolios.
| Feature | Single-Account Only | Household-Wide |
|---|---|---|
| Coverage | Only the trading account | Includes IRAs, 401(k)s, and spouse accounts [1] |
| Lot-Level Precision | CUSIP-level matching only | Lot-level matching plus substantially identical screening [4] |
| Timing | Post-trade reporting | Pre-trade blocking/prevention [2] |
| Auditability | Simple yes/no flag | Full derivation: loss-sale transaction, matching purchase, substantially identical determination basis, disallowance computation, and basis adjustment [4] |
This is where the gap can get sharp. A single-account setup may work for narrow use cases, but household-wide logic reaches across linked accounts and checks the full chain of what happened and why [1][2][4].
| Criterion | Light Constraints | Heavy Constraints |
|---|---|---|
| Tax Savings Potential | Moderate; broad index funds | Maximum; direct indexing, single stocks |
| Tracking Error | Low; highly correlated ETF swaps | Higher; factor-based replacement needed |
| Trading Costs | Low; infrequent rebalancing | Higher; frequent, optimized trades |
| Client Fit | Mass-affluent accounts; simple needs | High-net-worth accounts; concentrated positions |
In plain English, light constraints keep things simpler and cheaper. Heavy constraints can push for more tax value, but they also bring more trading, more drift risk, and more moving parts.
These trade-offs feed directly into the pros and cons below.
Each API model shines in a pretty narrow lane. This table cuts the choice down to four things that tend to matter most: speed, compliance scope, household visibility, and portfolio control.
| API Model | Strengths | Trade-offs | Ideal Deployment | Common Failure Modes |
|---|---|---|---|---|
| Event-Driven | Highest tax alpha; continuous monitoring can reach up to 1.25% annually [1] | Heavy API load; needs real-time data feeds and rate-limit management | HNW clients; direct indexing platforms | False triggers on small positions; API rate-limit breaches |
| Batch-Oriented | Low cost; simple scheduled setup; fits standard custodial feeds | Misses many chances versus hourly scanning | Standard retail robo-advisors; simple diversified portfolios | Losses that recover before end-of-day go uncaptured |
| Rule-Engine | Custom thresholds by tax bracket and position size; allows advisor approval gates [2] | Needs rule upkeep; struggles with "substantially identical" security determinations | HNW advisory firms; multi-state tax planning scenarios | Misclassifying holding periods; missing year-end distributions |
| Wash-Sale Compliance | Closes the outside-account gap; pre-trade blocking across IRAs, 401(k)s, and spouse accounts [1][4] | Needs multi-custodian data aggregation; high setup complexity | Multi-account households; multi-custodian RIAs | Trade-date boundary errors; missed 401(k) auto-purchases |
| Portfolio Optimization | Coordinates harvesting with rebalancing control and ESG constraints; key for direct indexing [3] | Highest implementation complexity | Institutional and enterprise direct-indexing programs | Unintended factor tilts; rebalancing engine repurchasing a recently harvested security [4][6] |
The trade-off is straightforward: more automation improves speed, but broader control makes implementation harder.
The right model comes down to latency, compliance scope, and operating complexity. In plain English: how fast the system needs to react, how much compliance it has to cover, and how much control the platform wants to keep.
Start with batch if you need the simplest operating model.
As timing starts to matter more, event-driven monitoring is the next move. Move to event-driven when intraday losses are worth the added complexity.
Rule engines and wash-sale APIs are necessary once a platform handles linked household accounts. Rule engines manage trade governance. Wash-sale APIs block disallowed losses across taxable accounts and linked household accounts. Cross-account purchases, especially in retirement accounts, are a common wash-sale failure point.
At scale, these pieces usually work better as a layered system instead of a single API. For large U.S. platforms, hybrid architectures are usually the best fit. That layered setup helps surface more opportunities without giving up compliance.
The best API model comes down to your firm’s needs: how often you want monitoring, how strict your compliance setup is, and how deeply the API needs to plug into your stack.
If your goal is to maximize tax alpha, continuous or hourly monitoring usually beats daily batch jobs. Why? Because market swings can create short-lived chances, and a once-a-day check can miss them.
It also helps to look for broad wash-sale coverage across held-away accounts, IRAs, and spouse accounts. On top of that, pay attention to dynamic thresholds and configurable advisor approval gates so the system fits how your firm actually works.
Event-driven tax-loss harvesting is worth the added cost only when the tax alpha it produces is greater than the related fees, trading costs, and tracking burden.
That tradeoff matters because losses can disappear fast. In many cases, they reverse within 8.3 trading days. So, hourly or real-time monitoring can spot chances that batch-job systems miss.
Put simply: if the extra tax savings are higher than the platform’s added cost, the upgrade makes sense.
Use a household-level system that tracks all client and spousal holdings together, including IRAs and 401(k)s. That matters because the wash-sale rule applies across accounts the taxpayer controls.
The system should keep a real-time restricted list after a harvest and block purchases of substantially identical securities across the household during the 61-day wash-sale window.


