Published on
June 19, 2026


If money moves through your system, audit, consistency, and recovery matter more than service count. I’d boil this article down to one point: split services by finance domain, keep the ledger strongly consistent, isolate compliance-heavy data, and keep reporting off the live transaction path.
Here’s the short version in plain English:
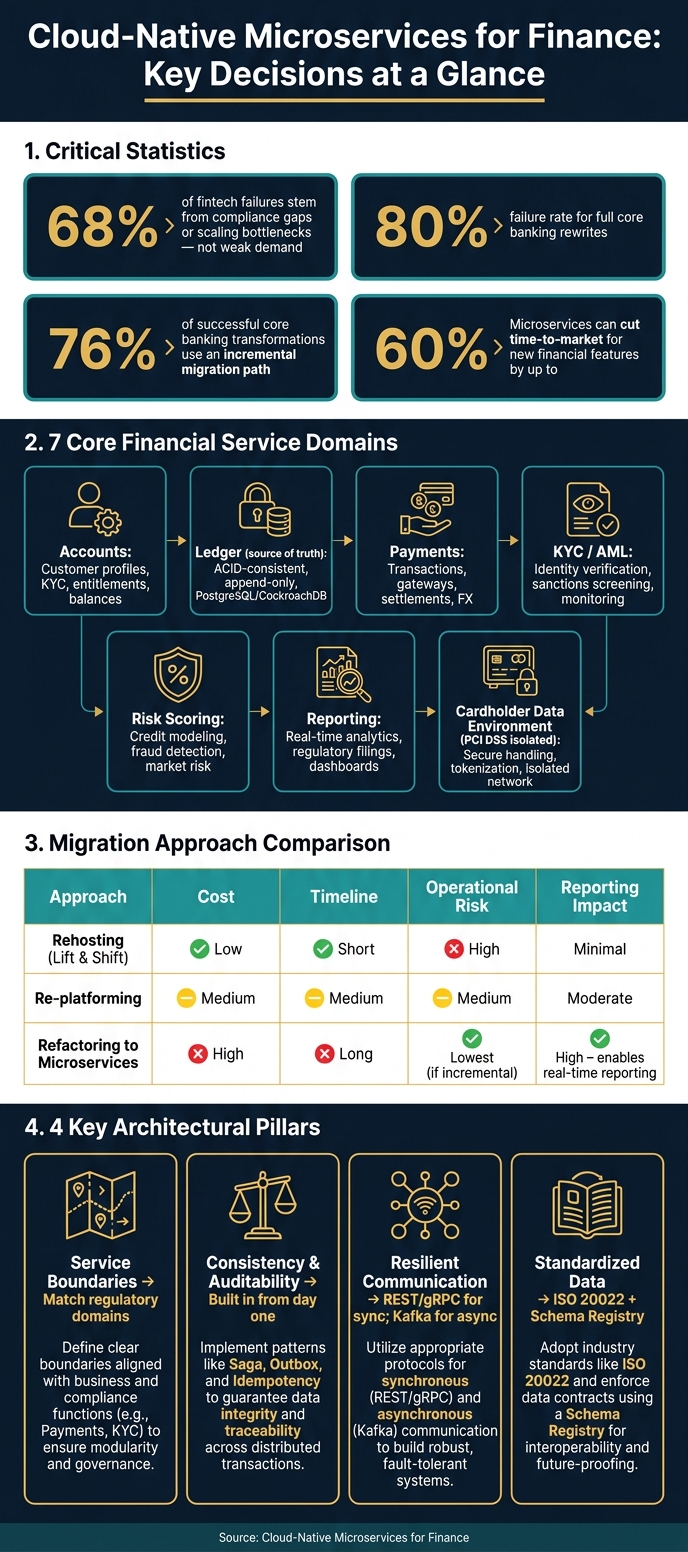
UPDATE and DELETE where needed, and make every state change traceable.One stat stands out: the article cites research saying 68% of fintech failures come from compliance gaps or scaling bottlenecks, not weak demand. It also notes that full core banking rewrites can fail at rates near 80%, which is why step-by-step migration tends to be the safer path.
This means the job is not just to “build microservices.” It’s to build a finance system that can post, trace, reconcile, recover, and prove what happened on demand.
Cloud-Native Financial Microservices: Migration Strategies & Key Stats
Before you build a service, define the rules it has to meet. In U.S. finance, the BSA, TILA, ECOA, SEC, FINRA, FFIEC, and CFPB set the bar for what must be logged, retained, and proven on demand. That changes how you design from the start.
In this space, service boundaries aren't just software boundaries. They're compliance boundaries and ledger boundaries too. Each one has to support three things: compliance, traceability, and financial correctness. Push those concerns to after launch, and teams often find themselves rebuilding core infrastructure when the pressure is highest. This is where fractional CFO services can provide the strategic oversight needed to align technical architecture with long-term financial goals.
Start with service boundaries. If those boundaries don't match regulatory accountability, gaps show up later. A service that mixes KYC/AML logic with payment processing is a good example. It may look convenient at first, but it creates a compliance mess that's tough to separate later.
Keep the Cardholder Data Environment (CDE) in its own service. That narrows PCI DSS scope.
Use Zero Trust as the default setup: mTLS for service-to-service calls, OAuth2/OIDC for identity, RBAC at the service layer, and policy-as-code in deployment pipelines so non-compliant resources can't be provisioned in the first place [1][6].
Audit logs should be append-only. Block UPDATE and DELETE at the database level [3]. These logs aren't just there for debugging. They're the evidence trail an auditor or regulator will ask for.
Once those access and audit boundaries are set, the next problem is keeping the ledger intact across services.
The ledger is the source of truth, so it must be strongly consistent. If you split ledger mutations across asynchronous services, you risk balance drift that's hard to spot and even harder to reconcile. Put simply, the ledger can't depend on other services to rebuild what happened.
Use ACID-compliant storage like PostgreSQL or CockroachDB for ledger entries. For transactions that span multiple services, use the Saga pattern instead of 2PC. Sagas use local transactions plus compensating logic when a step fails [3][5]. Then pair that with the Outbox Pattern so the state change and outbound event are written to the same local database atomically before publishing to Kafka. That helps prevent duplicate postings when the broker retries delivery.
That same setup also makes replay, reconciliation, and audit recovery much easier.
Every state-changing API call - especially payments - should require an idempotency key. If a request is retried after a timeout, the system checks the key before doing anything, which prevents duplicate charges or double entries [3].
Store audit timestamps in U.S. format, such as 06/19/2026, 2:34:07 PM. Use a schema registry so financial events stay readable and replayable for audits and disaster recovery [3].
Keep analytics off the transaction path. Route reporting and analytical workloads to a separate warehouse or read replica so transaction latency stays under control.
Once security and consistency rules are in place, the next step is the service map. In a cloud-native finance platform, that map usually has three layers: an API gateway, domain services, and an event bus.
At the edge, an API gateway like Amazon API Gateway or Kong handles authentication, rate limiting, and request routing. Behind that, domain services own specific business capabilities and their data. Those services connect asynchronously through a Kafka event bus. Authentication, authorization, and audit controls should exist at the gateway, service, and data layers. That structure decides how traffic, data, and controls move across the platform.
Split services by regulatory domain, not by technical convenience.
In plain terms, keep Accounts, Ledger, Payments, KYC/AML, Risk Scoring, and Reporting as separate services. Each service should own its own data and expose a clear API. The Cardholder Data Environment should be isolated to narrow PCI DSS scope.
Use REST or gRPC for low-latency authorization. Use Kafka for ledger posting, fraud screening, KYC verification, reconciliation, and reporting.
| Use Case | Communication Type | Pattern |
|---|---|---|
| Real-time authorization | Synchronous | REST / gRPC |
| Ledger posting | Asynchronous | Kafka + Outbox Pattern |
| Fraud screening | Asynchronous | Kafka (parallel consumers) |
| KYC verification | Asynchronous | Kafka (long-running workflow) |
| Monthly reporting | Asynchronous | Data pipeline |
For cross-service transactions, use orchestrated Sagas. To contain failures, use bulkheads. Orchestrated Sagas make transaction state traceable and auditable.
Use PostgreSQL or CockroachDB for ledger entries. For read-heavy workloads, CQRS separates the write path from the read path, so dashboards and reporting don't compete with transaction processing.
Send analytics and reporting to a separate warehouse such as Snowflake or BigQuery. Feed standardized transaction data into that warehouse for analytics, reporting, and audit replay.
Those data paths only work when deployment and observability enforce the same boundaries.
Architecture decisions only matter if the system runs well in production. So before anything goes live, teams need to lock down deployment controls, monitoring, and migration order. They also need release controls with fast rollback [1][7].
Kubernetes gives financial microservices self-healing, horizontal scaling, and namespace isolation. Networks, clusters, and policies should be defined in code and pushed through pipelines so each environment stays auditable and reproducible [1][7]. GitOps supports this setup by making Git the source of truth for both application and infrastructure state.
Before production, add static analysis, dependency scanning, and container image scanning [4]. Then match the release method to the type of change being shipped.
| Strategy | Risk Level | Rollback | Best For |
|---|---|---|---|
| Canary | Lowest | Instant (traffic shift) | Ledger changes, pricing engine updates, high-risk logic [1][7] |
| Blue-Green | Low | Fast (switch) | Major version upgrades, breaking API changes [1] |
| Rolling | Medium | Moderate | Routine patches, non-breaking reporting changes [7] |
For ledger or pricing updates, canary releases are usually the safer default. Sending a small share of traffic to the new version first gives teams a chance to catch latency drift or odd transaction patterns before a full rollout.
None of this works on autopilot. Deployment, rollback, and audit rules need clear ownership as part of the operating model.
Basic infrastructure monitoring - CPU, memory, and error rates - doesn't go far enough for financial systems. You need a three-layer observability stack: operational metrics through Prometheus and Grafana, end-to-end transaction tracing through Jaeger, and an immutable append-only audit log that records every write to a financial record [3][1].
Business signals matter just as much as system signals. Alerts should trigger on failed payment rates, reconciliation lag, settlement delays, and drops in transaction throughput - not only on pod restarts [1]. For finance teams, that makes it much easier to spot issues that can hit close processes, reporting accuracy, and settlement timing.
Those signals help only if teams can act on them. That comes back to clear service ownership and tight release discipline.
The Strangler Fig pattern is the go-to approach for modernizing core banking systems. It routes specific capabilities - one domain at a time - to new microservices while the legacy system stays live as a fallback [7][8]. That helps teams avoid a full rewrite, which has an 80% failure rate in banking [7]. About 76% of successful core banking transformations use an incremental path instead [7].
During the coexistence period, a Financial Anti-Corruption Layer (F-ACL) translates between legacy data models and new service schemas. Without it, old structures leak into the new architecture [7][8]. Change Data Capture (CDC) keeps the new system aligned with the legacy system of record by streaming row-level changes from the old database to Kafka [7].
| Approach | Cost | Timeline | Operational Risk | Reporting Impact |
|---|---|---|---|---|
| Rehosting (Lift & Shift) | Low | Short | High | Minimal; preserves legacy bottlenecks [1] |
| Re-platforming | Medium | Medium | Medium | Moderate improvements [7] |
| Refactoring to Microservices | High | Long | Lowest if incremental | High; enables real-time, granular reporting [1][7] |
These steps keep the books intact while the platform shifts to microservices piece by piece. The next issue is governance: who owns each service, each dataset, and each control.
Once the platform is live, ownership and standards are what keep financial controls in place. Each bounded context - Payments, KYC/AML, and Lending - should map to one cross-functional team. That team owns the service as its own auditable unit and is responsible for both development and compliance inside that domain.
If one service stretches across multiple regulatory domains, things can get messy fast. Ownership starts to blur. Accountability slips. That’s why it helps to assign clear owners for metrics, traces, and audit logs, so every operational alert points back to the right service owner.
At scale, two governance controls matter most.
That same discipline makes it easier for leadership to turn system data into finance output they can actually use.
Phoenix Strategy Group helps growth-stage finance teams connect cloud architecture and data engineering with bookkeeping, fractional CFO support, FP&A, and M&A readiness.
With ownership and standards in place, the last step is deciding what must stay consistent as the system grows. Microservices are worth the effort only when scale, compliance isolation, or release speed call for them.
The focus comes down to four decisions: service boundaries that match regulatory domains, consistency and auditability built in from day one, resilient communication patterns like Saga and the Outbox pattern, and standardized financial data definitions so the platform can change without losing traceability.
The best operating model ties architecture to measurable outcomes. Modern microservices can cut time-to-market for new financial features by up to 60% [2]. Those gains are possible when team ownership, governance, and observability are designed with the same care as the application architecture.
Finance platforms should use microservices when they need independent scaling for high-load parts, frequent low-risk releases, and a gradual path away from legacy systems.
This setup works best when customer-facing features like onboarding or notifications are split from logic that affects balances. That separation helps teams move faster on the front-end experience without constantly touching the parts of the system where mistakes can cost money.
But there’s a catch. Teams need the ops discipline to handle a distributed setup before they make the move. That means having distributed tracing and automated observability in place first. Without those, debugging a microservices system can turn into a mess fast.
The ledger must stay strongly consistent because it is the source of truth for financial assets. If concurrent writes or changes across separate services create mismatched states, you can end up with wrong financial results that are slow and painful to fix.
Strong consistency protects internal correctness. Entries stay balanced, and balances stay accurate. That matters for reconciliation and regulatory compliance.
A bank should take a disciplined, step-by-step path to cut risk and stay in line with regulatory rules. The best route is the Strangler Fig pattern: build new capabilities as microservices, then pull domains out of the legacy core bit by bit.
Before any coding starts, map business capabilities to bounded contexts with Domain-Driven Design. Then put an anti-corruption layer in place so the legacy model doesn’t bleed into the new system.


