Published on
June 19, 2026


API risk is simple: if you can’t tie each data pull or payment request to consent, identity, and a ledger record, you have a compliance problem.
I’d boil this article down to four points: track consent in real time, limit data access to what the product needs, map each API call to a verified person or service, and keep tamper-evident logs that can rebuild the full transaction path. That matters more now because the CFPB’s Section 1033 rule began its first compliance phase on April 1, 2026, NYDFS still has a 72-hour incident reporting window, and API systems under the CFPB framework must support at least a 95% request success rate.
If I were reviewing an API program today, I’d look for these gaps first:
Here’s the short version of what good control looks like:
| Risk area | What to check |
|---|---|
| Privacy and consent | Revocable, time-bound consent tied to each API call |
| Data governance | Field-level data minimization and named third-party access records |
| AML and fraud | Identity-based monitoring, sanctions checks, and rate limits |
| Audit and reconciliation | requestId linked to ledger entries, timestamps, hashes, and posting records |
| Vendor oversight | Due diligence, contract terms, subcontractor review, and log access |
I see this as less of a policy issue and more of a systems issue: the controls have to run inside the API flow itself, every time.
APIs create compliance risk anytime they share customer data, move money, or let a third party access an account. The hard part isn't only figuring out which rules apply. It's making sure your API controls enforce those rules all the time, not just during a policy review.
In the U.S., the main frameworks here are GLBA, the BSA/AML rules, CFPB Section 1033, and state cybersecurity rules like NYDFS Part 500. Each ties to a different business job. GLBA covers data access and vendor oversight. BSA/AML rules cover payment initiation and transaction monitoring. Section 1033 covers consumer authorization and data minimization. NYDFS Part 500 covers incident reporting and security program governance.
GLBA's Safeguards Rule (16 CFR Part 314) requires a written information security program to protect nonpublic personal information (NPI), and the 2023 amendments added nine specific security elements - including MFA, encryption, and activity logging - that directly affect API environments [5][6]. NYDFS Part 500 adds a CISO requirement, annual compliance certification, and 72-hour incident reporting for any entity holding a New York financial license [6].
On the AML side, the BSA does not distinguish between a wire transfer and an API-initiated value transfer. If your API moves money or enables account access, your KYC/KYB onboarding, OFAC sanctions screening, and transaction monitoring duties still apply. FinCEN assessed more than $2 billion in BSA/AML fines against fintech-adjacent firms in 2023 alone [6].
APIs strip out many of the checkpoints that batch and manual workflows used to provide. So consent, access control, and monitoring have to be built into the flow itself.
Section 1033 requires real-time tracking of authorization, revocation, and scope [1][8]. Your API stack must also support a minimum 95% success rate for data requests under the CFPB framework [10]. That's a big shift. Compliance is no longer just about having the right policy on paper. The system has to perform.
Data minimization matters too. API-collected data use is limited to what is reasonably necessary for the service and cannot be used for targeted advertising or sold to data brokers [7][10]. If your API pulls more fields than the product needs, you're creating privacy and compliance risk for no good reason.
Regulators look at API partners as an extension of your own institution. Under GLBA, you cannot contract away responsibility for how a vendor handles customer data [9]. That puts vendor due diligence, contract terms, and ongoing monitoring right at the center of API governance.
The Ascension Data & Analytics case shows what that risk looks like in practice. The FTC charged the vendor with violating the GLBA Safeguards Rule because its subcontractor, OpticsML, left sensitive mortgage data exposed on the internet for a year [9]. The takeaway is simple: your duty doesn't end with the company you signed.
Supervisors also expect accountability at the board and executive level. Every GLBA-covered entity must designate a qualified individual to oversee the security program [5]. NYDFS goes a step further by requiring an annual written certification of material compliance [6]. In day-to-day terms, that means documented risk assessments, vendor contracts, and proof that the governance model works in practice. Logging, reconciliation, and revocation controls matter just as much as vendor oversight.
Older control setups tend to break down when one transaction moves across several systems with different log formats, timestamps, and owners. The most common weak spots are fragmented logs, weak consent tracking, and poor data lineage. That problem gets worse when reporting windows are tight, like NYDFS's 72-hour requirement [6].
Legacy AML monitoring tools can also fall behind under API-driven volume. Rule-based systems tuned for batch inputs may miss patterns that only show up when you review continuous, high-frequency activity across many data sources. In plain English: suspicious activity can slip through before batch-based controls catch it. Those reconstruction gaps become the audit problem addressed next.
APIs create a traceability problem: every call has to line up with a clear consent scope and an authorized purpose. The hard part isn't only blocking the wrong access. It's being able to prove that every single call stayed inside the approved boundary.
Once consent and scope are set, the next risk is drift between what was approved and what the API sends back. This is where teams get into trouble. A common failure is collecting or returning more data than the service actually needs. APIs should enforce data minimization at the endpoint level, not just in policy [1].
Consent mapping is another weak spot. A lot of companies still handle consent like a one-time checkbox instead of a record tied to specific data scopes. Section 1033 requires annual reauthorization for data access [2]. If a customer does not reauthorize, data access must stop, and existing data may need to be deleted.
Third-party disclosures can create trouble too. Some state laws now require named third-party disclosures, not broad vendor categories [12].
The fix is to build authorization and logging directly into the request path, not treat them like a separate review step. APIs should expose only the fields a given use case needs, enforced through granular OAuth 2.0 scopes and PKCE [3]. That helps make sure third-party applications can access only what the customer explicitly approved.
Each access event should tie back to a consent record. Logs should include the timestamp, user, endpoint, method, and status code in tamper-evident, write-once storage that cannot be altered after creation [4][11]. Shared service accounts and generic API keys break attribution, so they don't cut it.
Audit logs must be kept for the period required by each applicable framework [4].
Real-time consent checks close the gap. APIs should verify a valid, non-expired consent token before each API call [11]. When a customer revokes access, that revocation should cascade at once to backups and downstream third-party partners.
Those same logs also become the evidence base for AML and fraud monitoring.
API speed can wreck AML and fraud controls when identity gets lost somewhere along the request path.
A lot of older monitoring setups still rely on global rate limits that don't account for identity. That means they can't tell the difference between normal internal traffic and a burst of micro-transactions pushed by a bad actor or a compromised partner [13]. That's a big problem.
Things get messier when an intermediary sits between the customer and the regulated firm. At that point, tying activity back to one verified user becomes much harder, and that gap can be used for synthetic identity fraud [3]. Orphaned admin accounts make the situation worse. Once identity drops out of the picture, alerts lose context and sanctions checks lose signal.
The fix starts with one rule: map every API call to a verified user identity before you monitor it or throttle it [4]. Put IAM at the gateway so rate limits and alerts work from verified identities, not anonymous traffic [13].
Then connect API gateway logs with AML and fraud systems. That way, odd access patterns and high-velocity micro-transactions can trigger automated alerts [4]. It also helps to lock down access with least-privilege rules and give every service and automation flow its own scoped identity. If credentials get compromised, the damage stays more contained [13][4].
Those same logs should also feed reconciliation and audit trails.
API logs need to do more than help engineers fix issues. They also need to support auditors, examiners, and fractional CFO services or internal finance teams. The main test is simple: can the log recreate the transaction for audit and reconciliation?
An HTTP 200 only shows that the message got through. It does not prove the business event finished. If you don't have invoice IDs, approval references, and posting confirmations, the record chain falls apart.
This gets messy fast when a transaction passes through a source system, middleware, and an ERP or another internal ledger. At each handoff, context can drop off. Then an examiner asks for the full chain, and you're stuck pulling records from several systems with mismatched timestamps and no shared ID connecting them.
| Element | Manual Audit Trail | API-Based Audit Trail |
|---|---|---|
| Timestamp | File metadata that can be edited | Server-generated ISO 8601 timestamp |
| Source Proof | Screenshots saved to shared drives, not tied to ledger | Timestamped screenshots in immutable storage, linked to ledger entry |
| Data Format | Inconsistent PDFs, screenshots, and paper | Normalized JSON or structured data |
| Transaction Chain | No programmatic link to the financial file | requestId maps directly to the ledger or application record |
| Searchability | Manual lookup by filename | Database-indexed by ID, date, or entity |
Manual reconciliation remains an "Achilles heel", said Joe Salvatore, Chief Risk Officer at Idea Financial [14].
Each API call should connect to the general ledger through a single requestId that maps to one internal record, such as a loan application, an invoice, or a settlement entry [14].
Logs also need to be tamper-evident. For SOX compliance, that usually means write-once, read-many (WORM) storage or cryptographic hash chaining, so past records can't be changed after the fact [14][4]. Growth-stage companies should set up immutable storage from day one. Doing it later can get expensive and painful [14].
Retention rules matter too. Most BSA records must stay on file for at least five years under BSA, seven years under SOX, and 10 years for OFAC records [14][4].
A defensible audit trail usually includes these core pieces:
Shared service accounts weaken that trail because regulators expect you to identify the specific person behind each API call [4].
| Required Log Field | Audit / Regulatory Objective |
|---|---|
| Unique Request ID | Proves completeness and prevents duplicate entries |
| User Attribution | Establishes authorization and individual accountability |
| ISO 8601 Timestamp | Establishes chronological order for cutoff testing and reporting |
| Raw Source Data | Preserves the original record for review |
| Decision Log | Shows the outcome and policy triggered |
| Payload Hash or Checksum | Helps prove the data was not altered in transit |
| ERP Posting Reference | Confirms the transaction was reflected in financial records |
For third-party verification workflows, capture screenshots or other visual proof right away. Vendor URLs often expire within 3 to 30 days, so those images need to be downloaded and stored locally or in immutable storage at the time of verification [14].
Dashboards should show business outcomes, not just system health. That means items like pending postings and unmatched settlements, not only latency or error rates [15]. It also helps to build an examiner export module early, so teams can produce PDF, CSV, or JSON evidence on demand.
These controls make audit evidence repeatable, searchable, and ready for review. Once the evidence ties back to the ledger, the next move is making the same controls work across teams and partners.
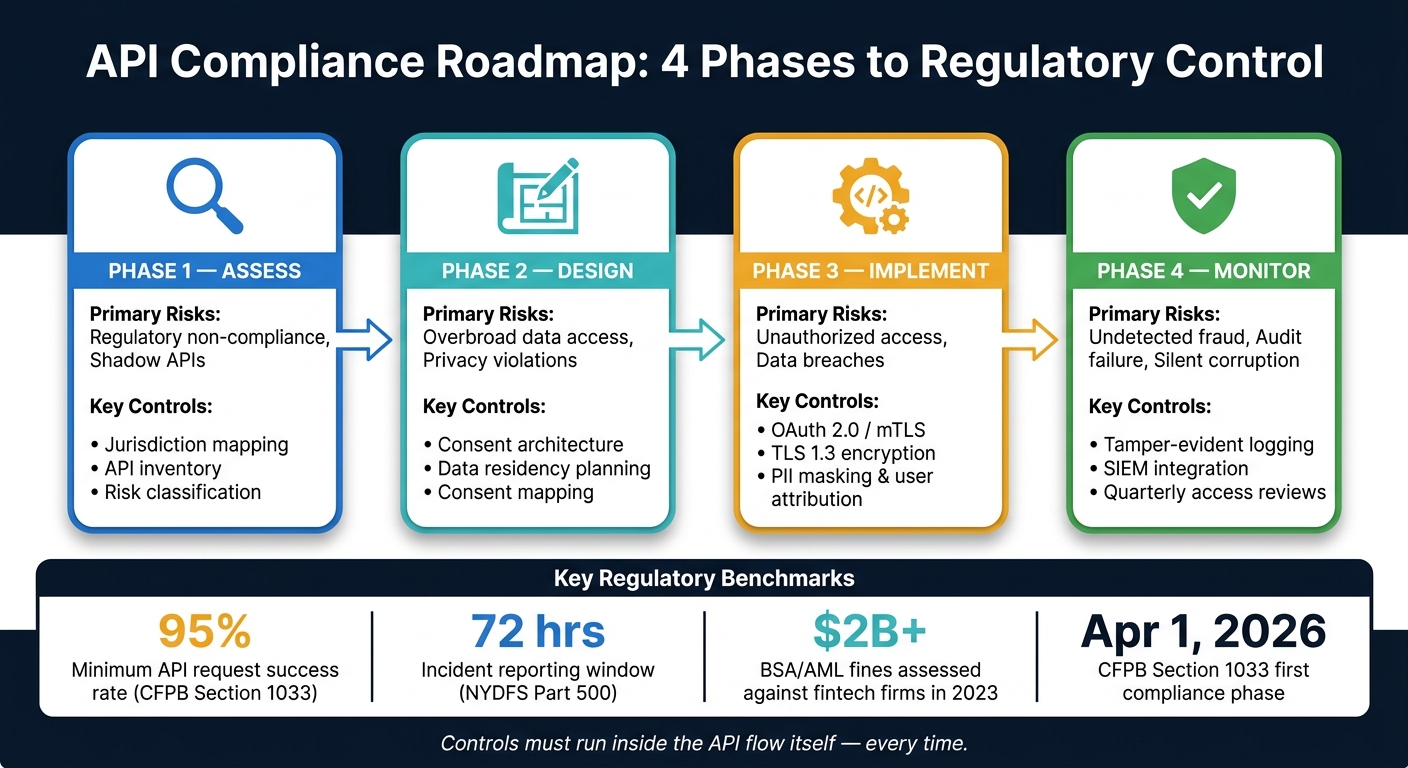
API Compliance Roadmap: 4 Phases to Regulatory Control
These controls work only when you build them in the right order. If you try to bolt on consent management or tamper-evident logging after launch, costs go up fast. It’s far cheaper to set the groundwork early than to patch holes later.
Use the sequence below to turn policy duties into build tasks. And don’t stop at naming a control type. Assign each phase to a clear owner.
| Phase | Primary Risks Addressed | Key Control Types |
|---|---|---|
| Assess | Regulatory non-compliance, shadow APIs | Jurisdiction mapping, API inventory, risk classification |
| Design | Overbroad data access, privacy violations | Consent architecture, data residency planning, consent mapping |
| Implement | Unauthorized access, data breaches | OAuth 2.0/mTLS, TLS 1.3, PII masking, user attribution |
| Monitor | Undetected fraud, audit failure, silent corruption | Tamper-evident logging, SIEM integration, quarterly access reviews |
The most common gap is individual attribution. Every API call should tie back to a named user, not a shared service account or a generic API key. That one detail makes a huge difference when something goes wrong and you need to know who did what. It also helps to assign a named API governance owner early and run quarterly access reviews so stale credentials and role changes don’t slip through.
API transactions create direct exposure across privacy, fraud, and financial reporting. The problem is that most older control setups were never built for real-time, multi-party data flows.
Once these phases are in place, the control model becomes repeatable. Four moves matter most:
For growth-stage companies that are scaling or getting ready for exit, these controls also support the financial integrity and operational visibility that deeper scrutiny demands. Phoenix Strategy Group helps growth-stage companies build the data infrastructure and financial reporting - across reconciliation, data engineering, and M&A readiness - that investor-grade traceability requires.
Valid API consent requires affirmative authorization from the consumer. In plain English, the consumer has to clearly say yes.
Under rules such as the CFPB’s Section 1033, that consent must also be purpose-specific. That means data can only be used for the tasks the consumer clearly approved, not for anything else added later.
Consumers must also be able to revoke access easily. On top of that, consent must be reauthorized annually.
Use individual user IDs instead of shared logins or generic service accounts. One common setup is OAuth 2.0 with OpenID Connect (OIDC). That gives you ID tokens with verified user details, which you can map to each person’s account.
For clean audit trails, include a unique user identifier in every API request and enforce authorization checks on the server side. RBAC can also help tie users to approved API scopes, which makes accountability and compliance much easier to track.
An effective API audit log needs to be tamper-resistant and chronological so teams can reconstruct what happened, step by step. At a minimum, it should record the user or system involved, ISO 8601 timestamps, the action taken, the resource affected, and the result of the request.
For configuration changes, the log should include the actor ID, IP address, user agent, request details, and the resource’s previous and updated state. It should also track data access, exports, modifications, and security-related decisions.


