Published on
January 5, 2026


Fraud costs businesses about 5% of annual revenue, and with 80% of banking data being unstructured, traditional systems often miss early fraud signals. Enter NLP: a game-changer in fraud detection. By analyzing emails, contracts, and user actions, NLP identifies patterns and behaviors that structured data systems overlook.
Key insights:
Solutions include improving data quality with synthetic sampling, boosting model accuracy with ensemble methods, and enabling real-time fraud detection through scalable architectures. Companies integrating NLP into systems reduce false positives, improve fraud detection rates, and stay ahead of evolving threats like AI-driven scams.

NLP Fraud Detection Techniques: Methods, Applications, and Real-World Results
Financial institutions deal with vast amounts of text-based information that traditional fraud detection systems often ignore. While these systems are great at analyzing structured data like transaction amounts or account numbers, they tend to overlook the roughly 80% of records that are unstructured [3]. This category includes emails, contracts, customer service logs, and regulatory filings - sources that frequently hide early signs of fraud. For example, a phishing email might use urgent, manipulative language to pressure someone, or inconsistencies in a contract could indicate deceptive practices. Natural Language Processing (NLP) steps in to transform this unstructured data into structured insights, making it easier for machine learning models to detect potential threats.
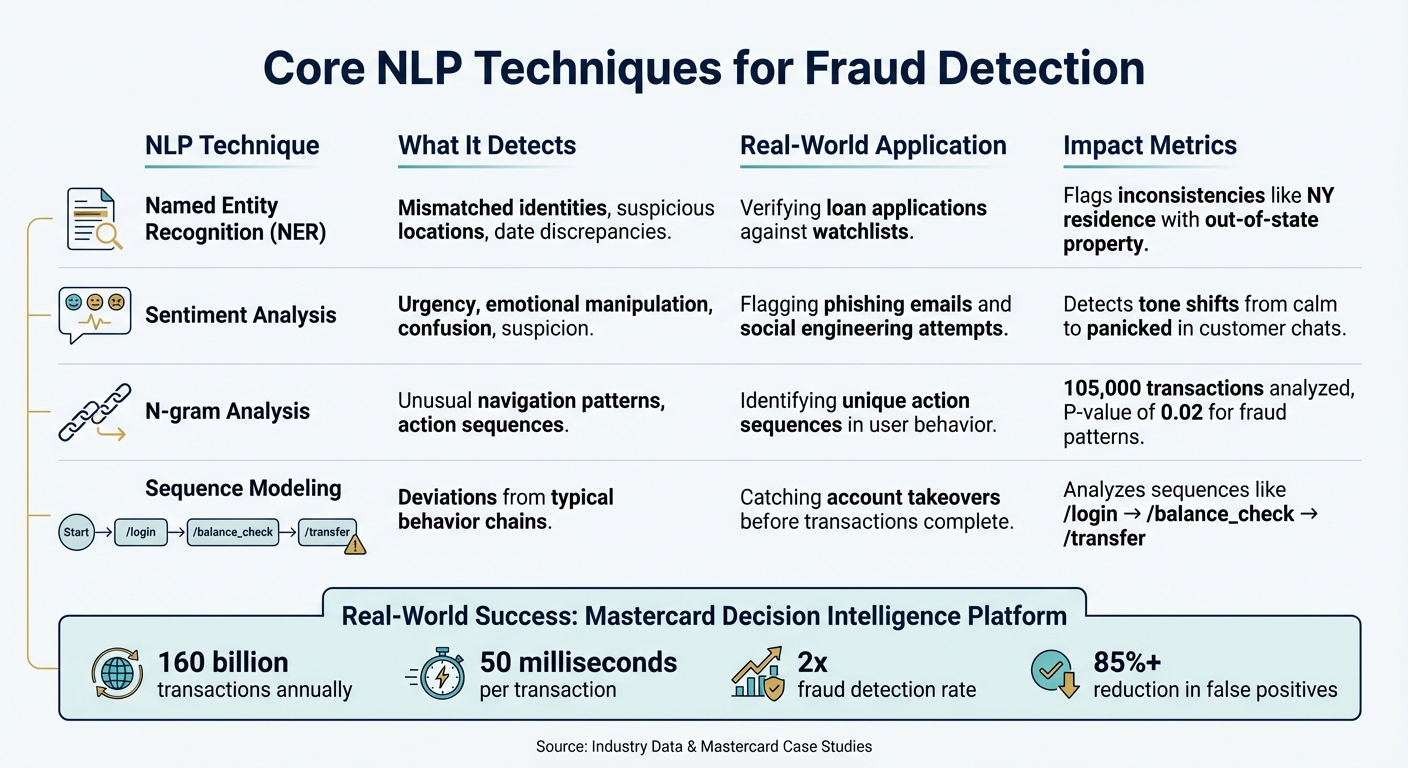
NLP tackles fraud detection through a variety of methods. One key technique is Named Entity Recognition (NER), which identifies names, locations, and dates to uncover discrepancies. For instance, imagine a loan application where the applicant claims to live in New York but lists property in another state with mismatched dates. NER can flag these inconsistencies for further review [3].
Sentiment analysis is another powerful tool, designed to pick up on emotional cues that could signal manipulation. It can detect urgency, confusion, or suspicion in communications - common tactics in phishing or social engineering schemes [6].
"Sentiment analysis enables the extraction of subjective qualities, attitudes, emotions, sarcasm, confusion or suspicion from text" [6].
For example, a sudden shift in tone during a customer service chat - from calm to panicked - might indicate fraudulent activity.
Sequence classification offers a different perspective by analyzing patterns in user behavior. A 2024 study using the FraudNLP dataset examined over 105,000 transactions from 2,000 users, treating API calls like words in a sentence. By applying TF-IDF to these sequences (e.g., /login, /balance_check, /transfer), researchers found that fraudulent transactions had distinct patterns in action trigrams, with a statistically significant P-value of 0.02 [1].
"Online actions do follow rules similar to natural language and hence can be approached successfully by natural language processing methods" [1].
Here’s a quick breakdown of how these techniques are applied:
| NLP Technique | What It Detects | Real-World Application |
|---|---|---|
| Named Entity Recognition | Mismatched identities and suspicious locations | Verifying loan applications against watchlists [3] |
| Sentiment Analysis | Urgency and emotional manipulation | Flagging phishing emails and social engineering [6] |
| N-gram Analysis | Unusual navigation patterns | Identifying unique action sequences [1] |
| Sequence Modeling | Deviations from typical behavior chains | Catching account takeovers before transactions complete [1] |
These methods are already proving their value in fraud detection. Take Mastercard’s "Decision Intelligence" platform, for example. In June 2025, the system demonstrated how NLP techniques can work at scale. By processing over 160 billion transactions annually, it combines behavioral history, purchase context, and device-level biometrics to assess risk in just 50 milliseconds. The results? Fraud detection rates doubled, and false positives dropped by more than 85% [7].
This kind of progress shows how NLP is reshaping the way financial institutions tackle fraud, turning complex patterns into actionable insights.
Fraud detection using NLP faces some tough challenges. One of the biggest hurdles is the severe class imbalance - fraudulent transactions are incredibly rare, sometimes making up as little as 0.096% of cases. For example, in one dataset, only 101 out of 105,303 transactions were flagged as fraudulent [1]. Another challenge is converting structured, high-dimensional financial data into natural language without sacrificing accuracy [5].
Privacy regulations further complicate the process. Compliance rules often require removing sensitive details like names, usernames, and IBANs. While necessary, this anonymization strips away contextual clues that could help detect suspicious activity [1]. On top of that, label noise adds another layer of difficulty. Datasets can contain "unlabeled" fraud - cases of illicit transactions that were never caught or reported. This means models may inadvertently learn from mislabeled examples, treating fraudulent cases as legitimate [1].
"A computer that's given messy, unprocessed text will likely generate poor results." - Salesforce [8]
Striking the right balance in fraud detection is tricky. Too many false positives increase costs and frustrate customers [1][9]. On the other hand, false negatives - missed fraud cases - can lead to direct financial losses [1][4].
For real-time fraud detection, precision is key. High-precision algorithms help reduce false positives and ensure legitimate transactions aren't unnecessarily blocked [1][9]. When analyzing historical data, however, the focus shifts to recall. High-recall methods aim to uncover as many missed fraudulent cases as possible [1][9]. Traditional accuracy metrics can be misleading in this context since a model might achieve high accuracy simply by ignoring the rare fraudulent cases altogether [1][2].
The situation becomes even more challenging due to the adversarial nature of fraud. Fraudsters constantly adapt their methods, and some are now leveraging tools like ChatGPT to create more sophisticated phishing campaigns and deepfakes [4]. It's estimated that organizations lose about 5% of their annual revenue to fraud globally [2].
"High recall is essential in scenarios where missing a fraudulent transaction is costly, while high precision is critical to minimize false alarms." - Nilesh Jain and Shalmali Patil, IJGIS [9]
These trade-offs highlight the need for efficient strategies, especially in real-time scenarios.
Real-time fraud detection introduces a different set of challenges. First, advanced AI models must process millions of transactions daily, requiring automated solutions that operate with low latency [1][5][9]. Second, converting structured financial data into text can result in long, noisy prompts that exceed context limits [5]. Third, delays in receiving verified fraud labels - feedback from confirmed cases - make it difficult to evaluate model performance in a timely manner [10].
"Real-time evaluation of fraud detection models is challenging since feedback (i.e., verified fraud cases) is often delayed, making it difficult to gauge the model's performance accurately." - Ishwarya S [10]
This creates a frustrating paradox: fast processing is critical to prevent fraud, but the accuracy of these models often can't be confirmed until long after the transactions have been processed.
Here’s how challenges like data scarcity, model precision, and processing speed can be tackled effectively.
When fraud data is scarce, techniques like SMOTE (Synthetic Minority Oversampling Technique) can generate synthetic samples, while ENN (Edited Nearest Neighbors) helps reduce noise in datasets [10][12]. Another powerful approach is incorporating human-in-the-loop (HITL) workflows, where fraud investigators label transactions flagged by models. Over time, this builds a trustworthy "ground truth" dataset [11]. For instance, sequences of user actions - like logging in, checking balances, and making transfers - can be treated as "sentences" for NLP analysis [1]. By modeling these action sequences as text, methods like TF-IDF and LSTM have shown to outperform traditional fraud detection techniques [1].
"Accurate data labeling ensures better quality assurance within machine learning algorithms, allowing the model to train and yield the expected output. Otherwise, as the old saying goes, 'garbage in, garbage out.'" - IBM [11]
Combining multiple models through stacking ensemble methods - such as XGBoost, LightGBM, and CatBoost - can catch fraud patterns that single models might miss. This approach has delivered impressive results, achieving 99% accuracy, a 0.99 AUC-ROC, and perfect fraud-class precision (1.00) while minimizing false positives on a dataset of 113,000 legitimate transactions [12]. Tools like SHAP (SHapley Additive Explanations) make these models more transparent by identifying the most critical features for fraud detection, which helps eliminate unnecessary data and noise [12]. For real-time applications, fine-tuning the classification threshold using the F₀.₅ score can strike a balance between precision and false alarms [12]. These improvements in accuracy underline the importance of fast, scalable processing.
Real-time fraud detection is a game-changer for preventing financial losses. In March 2021, Google Cloud and Quantiphi introduced a serverless architecture for fraud detection. This system used Cloud Dataflow for streaming data ingestion, BigQuery ML for training XGBoost models, and Cloud Firestore for quick lookups of user history. Hosting models directly on Dataflow workers reduced processing time to just a few seconds [13].
For high-speed data streams, Very Fast Decision Trees (VFDT) are a reliable choice [2]. Additionally, NoSQL databases like Firestore or Bigtable excel at real-time calculations, such as identifying patterns in transaction frequency and volume [13]. When deep learning models are too slow for production environments, knowledge distillation can create lightweight versions that retain accuracy while operating at faster speeds [2]. These strategies ensure both scalability and efficiency in fraud detection systems.
Fraud detection systems are already in place across many organizations, but enhancing them with Natural Language Processing (NLP) can uncover subtle fraud signals that might otherwise go unnoticed. By integrating NLP, companies can address challenges like data scarcity and processing delays while improving data quality, reducing false positives, and enabling real-time analysis.
Rule-based systems are great for handling straightforward scenarios, like flagging transactions that exceed account balances or originate from unusual locations. However, fraudsters are constantly evolving, and static rules often fail to keep up with their increasingly sophisticated tactics.
A hybrid orchestration approach can bridge this gap. Here’s how it works: rules act as the first filter, catching obvious issues, while NLP models dive deeper, analyzing complex patterns and assigning probability scores to suspicious activities. For example, a study on online banking transactions showed that incorporating NLP-based sequence features boosted the F1 score of a Random Forest classifier by 0.15 compared to using only traditional numerical data [1].
This hybrid system often employs a Direct Acyclic Graph (DAG) structure. In this setup, rules are represented as nodes in the graph. When a rule is triggered, the system calls an NLP model - managed through tools like MLflow - to calculate a fraud risk score [14]. This approach combines the speed of rule-based checks with the adaptability of machine learning. As Databricks puts it:
"Rules lack a spectrum of conclusions and thus ignore risk tolerance since they cannot provide a probability of fraud" [14].
By adding NLP to the mix, systems gain the ability to understand context and adapt to evolving fraud tactics. This hybrid strategy lays the groundwork for building more comprehensive fraud detection frameworks.
The most effective fraud detection systems don’t rely on a single method. Instead, they integrate multiple technologies - NLP, machine learning, graph analysis, and anomaly detection - into a unified framework. Each component plays a specific role: NLP evaluates text and behavioral patterns, graph algorithms uncover networks of related fraudulent accounts, and machine learning models analyze numerical transaction data. Together, these tools address issues like model transparency and real-time processing constraints.
A critical step in this integration is formatting data correctly. Most legacy systems only process numeric inputs, so textual data must be transformed into word embeddings before being fed into existing models. Meanwhile, data scientists can focus on updating NLP models, while business analysts refine the rule sets independently [14][15]. As Shayan Sadeghieh, a Machine Learning Engineer at Ravelin, explains:
"Machine learning systems are perfect for the dynamic and fast-paced nature of fraud... The only snag is that machine learning models can only understand numbers" [15].
To ensure real-time performance, the system’s infrastructure must support parallel model calls without causing delays. Lightweight wrappers, such as MLflow’s pyfunc, can manage this by loading both rules from cloud storage and NLP models from a registry simultaneously during inference [14].
In the United States alone, businesses lost $42 billion to fraud in 2019, with nearly half of companies experiencing fraud in the previous two years [14]. Given the sophistication of modern threats, adopting an adaptive, unified framework is no longer optional - it’s a necessity for staying ahead of fraudsters.
Choosing the right NLP tools depends heavily on your team's expertise and the specific needs of your operations. If your team works primarily in Python, spaCy is a great choice for fast, industrial-grade text analytics, while NLTK is well-suited for teams that need comprehensive documentation to build foundational NLP skills [17]. For enterprise environments using Java, Apache OpenNLP integrates seamlessly into existing workflows.
The context of your deployment also plays a major role. Real-time fraud prevention calls for high-precision algorithms to avoid unnecessary disruptions for legitimate users. On the other hand, historical fraud analysis leans on high-recall methods to identify missed fraudulent activity [1].
If your organization lacks deep learning expertise, managed services such as Google Cloud AutoML or IBM Watson can simplify the process with pre-built solutions. However, as content consultant Laurie Mega points out:
"Open source doesn't always come with out-of-the-box solutions, which could mean a lot of development and testing before anything works" [17].
For teams with technical resources, custom builds using frameworks like TensorFlow or spaCy offer more flexibility but require ongoing maintenance and development. Regardless of the tools you select, continuous monitoring is essential to ensure your models remain effective over time.
Traditional accuracy metrics often fall short in fraud detection because fraudulent cases make up less than 0.1% of the data [1]. Instead, focus on metrics like the Area Under the Precision-Recall Curve (AUPRC), which better captures performance for rare fraud cases. For real-time detection, the F₀.₅ score helps reduce false positives, while the F₂ score is more useful for offline audits, where catching as many fraudulent cases as possible is the goal [1].
Fraud patterns shift rapidly, so automated drift detection is critical. This ensures models are retrained promptly when data patterns change. Incorporating active learning loops - where fraud investigators review flagged transactions and provide labels - can immediately improve model accuracy and adaptability [10].
To implement NLP successfully, your organization must foster collaboration across multiple departments, including IT, data science, legal, compliance, and customer service. With U.S. consumer scam losses projected to hit $12.5 billion in 2024 - a 25% jump from the previous year - the stakes are too high for teams to work in silos [19].
Adopting cloud-native architectures and FinOps practices can help manage the computational costs of AI. As Maahir Azlaan explains:
"FinOps... brings together finance, technology, and business teams to ensure that cloud costs are aligned with business goals and that financial accountability is maintained throughout the cloud lifecycle" [18].
To protect sensitive information during model training and deployment, implement data masking techniques. For organizations with limited access to fraud data, leveraging transfer learning with pre-trained models can significantly enhance performance, even on smaller, specialized datasets [20].
Advanced NLP integration is reshaping fraud detection by improving how data is analyzed and how systems adapt to new challenges. However, implementing NLP effectively in this space requires addressing hurdles like data quality, model accuracy, and seamless system integration. Organizations that tackle these obstacles head-on can build stronger defenses against increasingly complex fraud tactics.
One effective approach involves modeling user actions - like logins, balance checks, and transfers - as text to uncover fraud patterns. For example, American Express saw a 6% boost in fraud detection accuracy, while PayPal improved real-time detection by 10% using advanced AI solutions [16]. These advancements demonstrate how refined analytical techniques can lead to more dependable fraud prevention systems.
At the heart of any effective fraud detection strategy lies high-quality data. Techniques like importance-guided feature reduction can identify the 10–20 most impactful attributes, cutting through noise and ensuring the data stays within the context limits of large language models (LLMs) [5]. Additionally, methods like SMOTE help address class imbalances, which often skew fraud detection outcomes.
Keeping up with evolving fraud tactics is equally critical. Automated drift detection can flag outdated training data, while active learning loops - where fraud investigators label flagged transactions - ensure models stay current [10]. By continuously refining these systems, AI tools can distinguish between legitimate transactions and suspicious activities, even spotting trends that human agents might overlook [16].
For real-time fraud detection, using high-precision algorithms (F₀.₅) reduces false positives. Meanwhile, high-recall methods (F₂) are ideal for offline audits, as they help uncover additional fraud cases [1]. Combining supervised learning for known patterns with unsupervised anomaly detection allows organizations to identify both familiar and emerging fraud tactics effectively [9][16].
Natural Language Processing (NLP) plays a crucial role in fraud detection by making sense of unstructured text data, such as transaction details, emails, or regulatory documents. By analyzing this data, NLP can uncover anomalies and spot suspicious patterns. It can also extract critical pieces of information, identify unusual language usage, and evaluate sentiment to help flag potential fraudulent activities.
On top of that, NLP models can treat sequences of user actions - like online transactions or account activities - as if they were linguistic tokens. These sequences are then processed with advanced machine learning techniques to pinpoint behaviors that stray from the norm. This method not only boosts the speed and precision of fraud detection but also cuts down on the need for manual intervention.
One of the biggest hurdles in tackling fraud detection is the scarcity and uneven quality of labeled fraud data. This data often comes with a severe class imbalance, where fraudulent cases are vastly outnumbered by legitimate ones. This imbalance makes it tough for models to effectively learn and identify fraud patterns. On top of that, handling high-speed, unstructured data streams in real time - while keeping latency low - adds another layer of complexity.
Another pressing challenge is maintaining model accuracy over time. Fraudsters are constantly changing their tactics, which means models need to keep up with these evolving patterns to stay effective. For Natural Language Processing (NLP) models, this means regular monitoring, retraining, and fine-tuning to adapt to new behaviors. Overcoming these obstacles demands advanced data engineering solutions and strong strategies for managing and updating models.
To improve the quality of data in NLP-based fraud detection, businesses should focus on cleaning and standardizing raw text data. This involves steps like normalizing dates into formats such as MM/DD/YYYY, ensuring monetary values follow a standard like $12,345.67, and unifying identifiers. Other important tasks include removing HTML artifacts, fixing spelling errors, and filtering out non-English or nonsensical entries. Automated tools, such as entity recognition, can streamline this process by standardizing critical elements like account numbers, IP addresses, and merchant names.
Given that fraud datasets are often limited and closely guarded, adding high-quality public resources can help expand vocabulary coverage and minimize bias. For datasets with class imbalances, strategies like oversampling or generating synthetic data can help maintain the integrity of labels without compromising accuracy.
To ensure long-term data quality, businesses should adopt continuous data monitoring. This helps identify shifts, such as the use of new slang or emerging fraud tactics, and allows for timely model retraining. Additionally, implementing clear quality-control measures - such as dataset versioning and setting minimum accuracy standards - can create a scalable and reliable pipeline that keeps pace with your organization’s evolving needs.